技術企業はソフトウェア開発に対するAIの影響をどのように測定しているのか
(newsletter.pragmaticengineer.com)- AIコーディングツールの広範な導入とコスト増加が進む中、有名テック企業が実際にAIの有用性を数値化する方法を多層的な指標として整理
- 中核となるのは、既存のエンジニアリング基本指標(例: PRスループット、変更失敗率)とAI専用指標(例: AI利用率、時間削減、CSAT)をあわせて追跡するハイブリッドなアプローチ
- チーム・個人・コホートごとにAI利用レベルに応じて分解し、導入前後の比較を通じてトレンドと相関関係を導き出す実験的な思考法を強調
- 品質・保守性・開発者体験を速度指標とあわせて常時監視し、技術的負債の増加と短期的便益の逆効果を防ぐバランス設計が必要
- 長期的にはエージェントのテレメトリや非コーディング業務領域まで測定対象を拡張することが示唆されており、問いは「AIがすでに重要なもの(品質・市場投入までの速さ・開発者体験)をより良くしているか」に帰着する
AIインパクトをめぐる議論と測定ギャップ
- LinkedInなどでよく見られるように、AIが企業のソフトウェア開発のあり方を変えているという主張があふれている
- Google 25%、Microsoft 30% など、大規模なAI生成コードが実際の本番コードとしてデプロイされているとの報道が続いている
- 一部の創業者は AIがジュニアエンジニアを置き換える と主張する一方、METRの研究 は時間感覚のゆがみと生産性低下の可能性を示している
- メディアはAIインパクトを**「どれだけ多くのコードを書いたか」へと単純化して伝えがちだが、その結果として業界は史上最大規模の技術的負債**が蓄積するリスクに直面している
- LOC(行数)は生産性指標として不適切だという合意があったにもかかわらず、測定のしやすさゆえに再び台頭し、品質、イノベーション、リリース速度、信頼性といった本質的な価値が見えにくくなっている
- 現在、多くのエンジニアリングリーダーは何が効果的で何がそうでないのかを明確に把握しないまま、AIツールに関する重大な意思決定を下している
- LeadDevの2025 AI Impact Report によれば、リーダーの60%が「明確な指標の欠如」を最大の課題として指摘している
- 現場のリーダーは成果への圧力とLOCに執着する経営陣の間で不満を抱えており、必要な情報と実際の測定とのギャップはますます広がっている
- 筆者は10年以上にわたり開発者ツールを研究しており、2021年以降は生産性向上とAIインパクト測定の助言を行っている
- DXのCTOとして参画後、数百社と協業しながらDevEx・効率性・AI影響分析を主導してきた
- 2025年初頭には、400社超の企業データをもとに AI Measurement Framework を共同執筆
- これはAI導入と影響測定に必要な推奨指標セットであり、現場研究とデータ分析を土台に構築された
- この記事では、18のテック企業が実際にAIインパクトを測定している方法を見ていき、
- Google、GitHub、Microsoft などの実際の指標事例
- 何が有効かを把握するための活用法
- AIインパクト測定の方法論
- AIインパクト指標の定義とガイドを共有する
1. 18社の実際の測定指標
- Google、GitHub、Microsoft、Dropbox、Monzo、Atlassian、Adyen、Booking.com、Grammarly など18社の事例を画像で共有
- 各社は異なるアプローチを取っているが、共通していくつかの主要な指標群に注目している
-
1. 利用指標 (Adoption & Usage)
- DAU/WAU/MAU: ほぼすべての企業がAIツールの日次・週次・月次アクティブユーザーを追跡
- 利用強度/利用イベント: Google、eBay などはコード作成、チャット応答、agentic actions まで細分化
- AI tool CSAT: Dropbox、Webflow、Grammarly など多くの企業が満足度調査を併用
-
2. 生産性指標 (Throughput & Time Savings)
- PRスループット(PR throughput): GitHub、Dropbox、Webflow、CircleCI など多くの企業が共通して追跡
- 時間削減(Time savings): エンジニアごとの週間削減時間を測定(Dropbox、Monzo、Toast、Xero など)
- PRサイクルタイム: Microsoft、CircleCI、Xero、Grammarly などで使用
-
3. 品質/安定性指標 (Quality & Reliability)
- 変更失敗率(Change Failure Rate): GitHub、Dropbox、Adyen、Booking.com、Webflow などで最も一般的な品質指標
- コード保守性/品質認識: GitHub、Adyen、CircleCI などがDevExと関連付けて評価
- バグ/差し戻し率: Glassdoor(バグ数)、Toast(PR revert rate)
-
4. 開発者体験指標 (Developer Experience)
- 開発者満足度/アンケート(DevEx, DXI): Atlassian、Webflow、CarGurus、Vanguard などで活用
- Bad Developer Days (BDD): Microsoft は独自に「悪い開発者の一日」という概念で摩擦を測定
- 認知負荷・開発者 friction: Google、eBay など
-
5. コストと投資指標 (Spend & ROI)
- AI支出(total & per developer): Dropbox、Grammarly、Shopify の事例のように、一部企業はコストを追跡
- Capacity worked(活用率): Glassdoor はツールが最大潜在力に対してどの程度使われたかを測定
-
6. イノベーション/実験指標 (Innovation & Experimentation)
- Innovation ratio / velocity: GitHub、Microsoft、Webflow などはイノベーション速度を指標化
- A/Bテスト数: Glassdoor は月間A/Bテスト件数を主要指標としている
- 時間削減、PRスループット、変更失敗率、参加ユーザー、イノベーション率などの成果指標と利用行動指標を並行して追跡している
- 組織ごとに優先順位と製品コンテキストに応じて指標構成は異なり、単一の万能指標は存在しない
2. 強固な基盤: AIインパクト測定の核心
- AIでコードを書くからといって、良いソフトウェアの基準が変わるわけではない。品質、保守性、速度は依然として中核的な要素である
- したがって、変更失敗率(Change Failure Rate)、PRスループット、PRサイクルタイム、開発者体験(DevEx) といった既存指標は引き続き重要である
- まったく新しい指標は不要
- 重要な問いは「AIは、これまで重要だったことをよりうまくできるようにしているのか?」である
- LOCや受容率のような 表面的な指標 にとどまると、AIのインパクトを正しく把握できない
- AI利用で正確に何が起きているのかを把握するには、新しいターゲット指標が必要
- AIがどこで、どれだけ、どのように使われているかを把握することで、予算・ツール展開・セキュリティ・コンプライアンスといった意思決定に活用できる
- AIメトリクスは次のようなことを示す:
- AIツールを導入している開発者の数とタイプはどれくらいか?
- AIはどれだけ多くの作業、またどの種類の作業に影響を与えているか?
- コストはいくらか?
- 中核的なエンジニアリング指標は次のようなことを示す:
- チームがより速く出荷できているか
- 品質と信頼性が上がっているか/下がっているか
- コードの保守性が低下していないか
- AIツールが開発者ワークフローの摩擦を減らしているか
-
Dropboxの事例を見ると
- AI指標
- DAU/WAU(日次・週次アクティブユーザー)
- AI tool CSAT(満足度)
- エンジニアごとの時間削減
- AI支出
- コア指標(Core 4 Frameworkを活用)
- Change Failure Rate
- PR throughput
- 成果
- 週次の定期的なAI利用者 = 全エンジニアの90%(業界平均の50%より高い)
- AIの定期利用者は PRマージが20%増加 + 変更失敗率が低下
- 導入率そのものよりも、組織・チーム・個人の成果に実質的に貢献しているか を確認することが重要である
- AI指標
3. AI利用レベル別の指標分解
- AIが開発者の働き方にどのような変化を与えるのかを理解するために、さまざまな比較分析を実施
- AI利用者 vs 非利用者の比較
- AIツール導入前後の中核的エンジニアリング指標の比較
- 同一ユーザー集団を追跡するcohort analysisによって、AI導入後の変化を観察
- データを細分化(slicing & dicing)してパターンを導き出す
- 役割、勤続年数、地域、主要言語といった属性ごとに分析
- 例: ジュニアはPR作成が増え、シニアはレビュー比重の増加で速度が落ちる現象
- これにより、追加の教育・支援が必要なグループ と AI活用効果が大きいグループ を識別できる
- Webflowの事例
- 勤続3年以上の開発者集団で、AI活用時の時間削減効果が最も大きかった
- Cursor、Augment Codeなどのツール活用時に PRスループットが20%増加(AI利用者 vs 非利用者の比較)
- 堅牢なベースラインの必要性
- 開発者生産性指標の基盤がない組織では、AIインパクトの測定が難しい
- Core 4フレームワーク(Dropbox、Adyen、Booking.comなどで活用)により、迅速にベースラインを確保できる
- テンプレートとガイド を参照
- システムデータ・経験サンプリングデータ・定期アンケートを組み合わせて、信頼性の高い比較を行う
- 継続的な追跡と実験的な思考法が重要
- 一度きりの測定では意味がなく、時系列での追跡 によって傾向とパターンを把握する必要がある
- 成功している企業の共通点: 具体的な目標を立て、データを通じて仮説を検証する
- データを盲目的に信頼するのではなく、目標中心の実験マインドセット を維持する
4. 保守性・品質・開発者体験に対する警戒
- AI支援開発は依然として新しい領域
- 長期的なコード品質・保守性への影響を証明するデータが不足している
- 短期的な速度向上と長期的な技術的負債リスクのバランスが重要課題である
- 相互にけん制し合う指標をあわせて追跡すべき
- ほとんどの企業は 変更失敗率(Change Failure Rate) と PRスループット を同時に追跡している
- 速度は上がっても品質が落ちる場合、これは即座の問題シグナルとして機能する
- 品質・保守性を監視するための追加指標
- Change confidence: デプロイ時のコード安定性に対する開発者の確信度
- Code maintainability: コードの理解・修正のしやすさ
- Perception of quality: コード品質や慣行に対するチームレベルでの開発者認識
- システム指標と自己申告指標の組み合わせが必要
- システムデータ: PRスループット、デプロイ頻度など
- 自己申告データ: 変更信頼度、保守性など → 長期的な悪影響を防ぐための重要なシグナル
- 定期的な開発者体験(DevEx)アンケートを推奨
- アンケート例 を通じて、品質・保守性とAI利用の相関関係を追跡できる
- 非構造化フィードバックも、既存課題の把握や解決策の議論に有用である
- 開発者体験(DevEx)の実際の意味
- 「卓球・ビール」のような福利厚生の概念ではなく、開発プロセス全体の摩擦を取り除くこと
- 企画→開発→テスト→デプロイ→運用という全工程での効率性確保を目指す
- AIツールはコード作成・テストの摩擦を減らす一方で、レビュー・インシデント対応・保守に新たな摩擦を加えるリスクがある
- 現場のインサイト(CircleCIのShelly Stuart)
- 出力指標(PRスループット)は 何 が起きているかを示すが、開発者満足度は 持続可能性 を示す
- AI導入は初期の不便をもたらす可能性があるため、満足度の追跡は 短期的な摩擦 vs 長期的な価値 を見分けるための重要なツールである
- 75%の企業がAIツールのCSAT/満足度もあわせて追跡 → 速度より 持続可能な開発文化 の醸成に焦点を当てている
5. 独特な指標と興味深い動向
- Microsoft: Bad Developer Day(BDD)
- 日常業務における摩擦や疲労度をリアルタイムで測定する概念
- インシデント対応・コンプライアンス処理、会議・メールの切り替えコスト、作業管理システムに費やす時間などが、一日を悪くする要因
- PR活動(コーディング時間の代理指標)とのバランスを見て、一部に低価値な業務があってもコーディング時間を一定程度確保できれば良い一日と評価
- 目標: AIツールがBDDの頻度・深刻度を減らしているか確認すること
- Glassdoor: 実験とツール活用率の測定
- 月間のA/Bテスト件数で、AIがイノベーション・実験の速度を高めているか追跡
- パワーユーザーを社内AIエバンジェリストとして育成する戦略も並行
- Capacity worked(活用率): ツールの潜在的な使用量に対する実際の使用量を測定し、導入の飽和時点や予算再配分の判断に活用
- Acceptance Rateの低下
- 過去には中核的なAI指標だったが、提案受け入れの瞬間しか見ないため範囲が狭い
- 保守性、バグ発生、コード差し戻し、開発者の体感生産性などは反映できない
- 現在は最上位指標としてあまり使われないが、例外はある:
- GitHub: Copilot改善と製品意思決定に活用
- T-Mobile: AIコードが実際の本番環境に反映される度合いを推定
- Atlassian: 開発者満足度および提案品質の補助指標として使用
- コスト・投資分析
- 大半の企業は開発者の萎縮を防ぐため、利用コストを積極的には追跡していない
- ShopifyはAI Leaderboardでトークン消費量の多い開発者を称賛する方式を採用
- ICONIQ 2025 State of AI Report: 2025年の企業内AI生産性予算は2024年比で2倍に増加する見通し
- 一部では採用予算を削減し、AIツール予算へ再配分する形へ転換
- エージェント・テレメトリーの不在
- 現時点ではほとんど測定されていないが、12カ月以内に導入される可能性が高い
- 自律型エージェントのワークフローが広がると、行動・精度・回帰率などを計測する必要性が高まる
- コーディング以外の活動測定の不足
- 現在はコード作成支援に限定され、ChatGPTでの企画セッションやJiraのイシュー処理などはあまり含まれていない
- 2026年にはSDLC全体の段階でAI活用が拡大し、測定も進化が必要
- コードレビュー、脆弱性検査のような具体的活動は測定しやすい一方、抽象的な作業は測定が難しい
- 自己申告型測定(「今週AIでどれだけ時間を節約したか?」)の適用範囲拡大が予想される
6. AIインパクトはどのように測定すべきか?
- AI Measurement Framework
- DevEx Frameworkの共同著者であるAbi Nodaとともに開発
- 400社あまりの企業の現場データと、過去10年余りの開発者生産性研究をもとに作成
- AI指標とコア指標を組み合わせ、速度・品質・保守性・開発者体験(DevEx)を合わせて評価
- 単一指標(例: AI生成コード比率)は見出しには適していても、十分な成果測定手段ではない
- 定性的 + 定量的データの併用が必要
- システム指標(PR処理量、DAU/WAU、デプロイ頻度など)と自己申告指標(CSAT、時間短縮、保守性の認識など)の両方を収集してこそ、多面的な理解が可能
- 多くの企業がDXを活用してデータ収集と可視化を行っており、カスタムシステムの構築も可能
- データ収集方法
- システムデータ(定量): AIツールの管理API(利用・支出・トークン・受け入れ率) + SCM・JIRA・CI/CD・ビルド・インシデント管理指標
- 定期アンケート(定性): 四半期・半期アンケートでDevEx・満足度・変更への信頼性・保守性など、システム指標では得にくい長期的トレンドを把握
- 経験サンプリング(定性): ワークフロー中に短い質問を挿入(例: PR提出直後に「AIを使用したか?」「このコードは理解しやすかったか?」)
- 実行の優先順位
- 定期アンケートが最も速い出発点: 1〜2週間以内に初期データを確保可能
- カーテンを取り付けるときとロケットを打ち上げるときで必要な精度が違うように、エンジニアリングの意思決定では十分な方向性を与える程度の正確さでも意味がある
- その後、ほかのデータ収集方法を並行して用いて相互検証すれば信頼性が向上
- 追加リソース
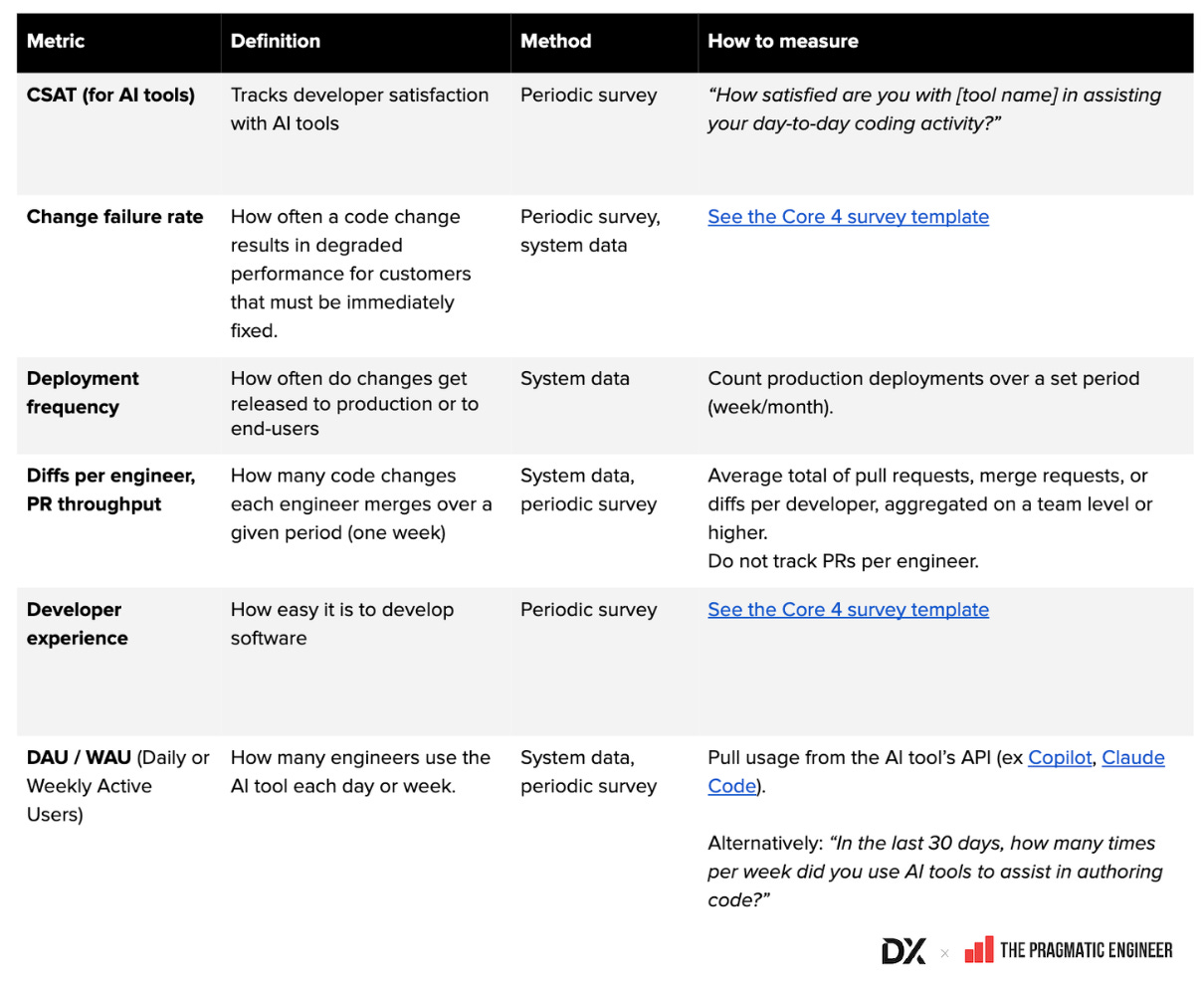
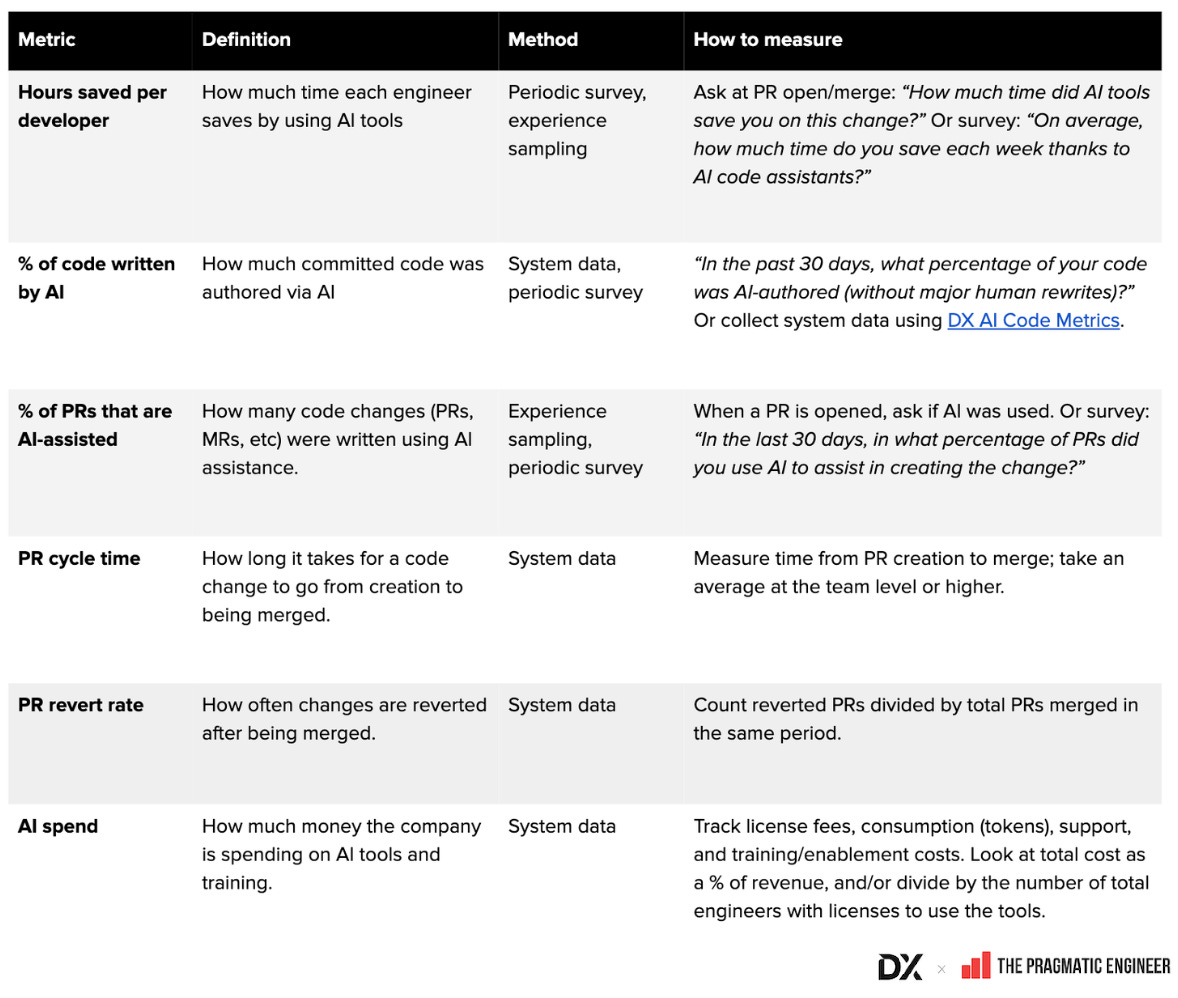
- 共通AI指標グロッサリー(Google Sheet): 定義・計算法・収集方法を整理
- AIおよび開発者生産性指標の例示画像
- 社内適用時の考慮事項
- 採用率や単一指標を追うのではなく、高品質なソフトウェアをすばやく顧客に届ける能力が向上しているかを確認すべき
- 重要な問い:
> 「AIは、すでに重要なもの(品質、リリース速度、開発者体験)をより良くしているか?」 - リーダーシップ会議で扱うべき質問:
- 私たちの組織におけるエンジニアリング成果の定義は何か?
- AIツール導入前の成果データは確保できているか? ないなら、どうすれば素早くベースラインを整えられるか?
- AI活動をAIインパクトと取り違えていないか?
- 速度・品質・保守性のバランスは取れているか?
- 開発者体験への影響は見えているか?
- システムデータと自己申告データの両方を含む多層的な測定方式を運用しているか?
{kind=link}
{kind=link}
7. MonzoのAIインパクト測定方法
- 導入初期
- 最初のツールは GitHub Copilot。GitHubライセンスに含まれており、VS Codeに自然に統合されているため、すべてのエンジニアが使い始めた
- その後 Cursor、Windsurf、Claude Code などさまざまなツールを並行してテストしつつ、Copilot中心で引き続き投資
- AIツール評価の哲学
- 急速に変化するツールのエコシステムでは、直接体験が不可欠
- チームメンバーが実際のコードにAIを毎日適用し、エージェント設定ファイルまで自ら作って使ってみてこそ性能が分かる
- 評価には 客観的指標(利用量、性能) と 主観的アンケート(DX満足度) を併用
- 効果と体感価値
- エンジニアはAIによって ドキュメント検索・要約・コード理解 が容易になり、認知負荷が減ったと感じている
- 競争の激しい人材市場 では最高のツールを提供しなければ開発者流出のリスクがあるため、ツール提供そのものが人材維持戦略になる
- 測定の難しさ
- ベンダーが提供する数値は 受容率のような限定的な指標 にとどまり、本当のビジネスインパクトは把握しにくい
- A/Bテストで正確に検証することも現実的には不可能
- さまざまなツール(GitHub、Gemini、Slack、Notionなど)の利用データを総合するのが難しく、テレメトリの制約とベンダーロックインが主な障害
- 結果として、現時点では 開発者の体感 が主なシグナルになっている
- うまく機能する領域
- マイグレーションで大きな成果があり、コード変更作業の40〜60%削減を体感
- データモデルの注釈作業のような反復的で手作業の多い仕事では、LLMが一次ドラフトを作成し、エンジニアが修正することで、大規模な労力削減につながる
- 予想外の教訓
- LLMコスト感覚の不足: 実際のトークン使用量に対する請求書を見れば、最適化の必要性をより強く実感するはず
- 例: Copilotの自動コードレビューはトークンを多く消費する一方で成果は少なく、デフォルトではオフにし、必要時に opt-in 方式へ切り替え
- AIを使わない領域
- 顧客データ関連: 元データ・非識別化データのいずれもAIへの適用を禁止
- 機密データ領域では データ漏えいリスク の防止を最優先としている
- プラットフォームチームの哲学
- Guardrailsの提供: データ保護など安全に使える環境を整備
- 事例共有: 成功・失敗事例やプロンプト活用の経験を透明に公開
- 両面性の強調: 良い面・悪い面の両方を共有し、バランスの取れた視点を維持
- LLMの限界を想起: AIにも人間のように限界があるため、過信しないよう注意を促す
結論と示唆
- AIインパクトの測定はまだ非常に新しい領域
- 業界に「最善の方法論」は存在しない
- MicrosoftやGoogleのように規模や市場が似ている企業でも、互いに異なる指標を使っている
- 企業ごとに 固有のやり方 と「flavor」が存在する
- 相反する指標を同時に測定するのが一般的
- 代表的な例: 変更失敗率(信頼性) と PR頻度(速度) を併せて追跡
- 迅速なデプロイは信頼性を損なわない範囲でこそ意味があるため、両軸をバランスよく測定する必要がある
- AIツールのインパクト測定は開発者生産性の測定と似た難題
- 生産性測定は10年以上にわたり業界が格闘してきた問題
- 単一の指標でチーム生産性を説明することはできず、特定指標に最適化しても生産性が実際に向上するとは限らない
- 2023年にMcKinseyは生産性測定法を「解決した」と発表したが、Kent Beckと筆者はこれに懐疑的な立場を示している → 反論記事
- まだ明確な解決策はないが、実験は必要
- 生産性測定を完全に解決するまでは、AIツールのインパクト測定も完全には解決しにくい
- それでも 「AIコーディングツールが個人・チーム・会社単位の日次/月次の効率性をどう変えるのか?」 という問いに答えるため、実験を続け、新しいアプローチを試みる必要がある
まだコメントはありません。